reCAPTCHA, bilmeyenler için, Facebook-Twitter gibi bir çok büyük sitede kullanılan ve iki kelimeden oluşan resimli “güvenlik kodu” uygulaması. Aslında yaptığı şey, Google Books tarafından taranıp internete aktarılan 10 milyondan fazla [1] kitabın OCR okuyucular tarafından okunamayan kısımlarının kullanıcılara okutulması. Son zamanlarda Google tarafından satın alınan [2] reCAPTCHA ile aslında kullanıcılar girdikleri kelimeler ile OCR okuyucularının okuyamadığı kelimeleri insanı hesaplama kabiliyetlerini kullanarak okuyorlar, hem de bir güvenlik doğrulaması sağlanmış oluyor. Bir süredir üzerinde kafa yorduğum konulardan biri de human based computation. Bir şekilde insanların beyin gücünü kendi uygulamanızın faydası için kullanıyorsunuz. CAPTCHA’nın (basit güvenlik kodu sistemi) yaratıcısı genç profesör Luis von Ahn tarafından Carnegie Mellon’da geliştirilen reCAPTCHA aslında başlarda sadece OCR sistemlerin okuyamadığı yazıları kullanıcılara okutmak için tasarlanıyor, ama daha sonralarda Google Books’un yüzlerce kütüphanede devam eden kitap tarama operasyonundan beslenmeye başlıyor.
Bu süre zarfı içinde Facebook, Twitter, StumbleUpon, CNN, 4chan gibi bir çok geniş kullanıcı kitlesine sahip oluyor. Bu sistemi sitelerine dahil eden _startup _sahiplerindeki motivasyon ise hem dünyaya faydalı olmak, hem de beraberinde getirdiği kolay kurulum ve kullanım. Daha sonralarda da sistem, Google tarafından satın alınıyor.
Yarım aklımla derlediğim birkaç argüman ile reCaptcha’nın aslında yeteri kadar güvenli bir sistem olmadığını ve işleyişindeki mantıksal zaafiyetleri anlatmaya koyulayım. Hiçbiri kuvvetli argümanlar değil, fakat sistem üzerine kritikler içeriyor. 8-)
# reCAPTCHA zaten okunabiliyor?
Asıl amacı OCR okuyucuların okuyamadığı yazıları okumak olan reCAPTCHA’nın sunduğu resimler, kasıtlı olarak güvenlik kodunu okuyabilecek program yazılamasın diye eğilip bükülüyor (water filtering). Zamanında reCAPTCHA’dan rastgele derlediğim 10 (x2) ’lik kelime setini www.captchakiller.com ‘da 100% başarıyla çözdürebilmiştim. İlginç ki captchakiller.com bir süredir kapalıymış, keşke açık olsaydı da canlı canlı gösterme fırsatım olsaydı. :)
Demem o ki, reCAPTCHA tarafından sunulan resimlerin çoğu sadece kitaplardaki fontların dar dar olması veya özel karakterler içermesiyle alakalı. Bu sayfada sunulan “low quality” kitaplar zaten taranan içeriğin düşük bir yüzdesini oluşturuyor, kaldı ki o kadar silik yazıyı zaten insanlar da okuyamıyor. Bu yüzden reCAPTCHA’nın sunduğu çoğu resim aslında başarılı ve hata toleransı olan bir tarama yazılımıyla okunabiliyor. :idea: O halde 10pt siyah Verdana font ile sadece 5 rakamdan oluşan güvenlik koduyla reCAPTCHA’nın bir farkı yok, ikisi de kötü amaçlı kişilerce rahatlıkla okunabilir. Zaten kötü niyetli kişinin hedefi %100 başarı da değil. Captcha’yı ne kadar geçerse, o kadar kâr. ;)
# Oylama Sistemi Kötüye Kullanılabilir
Kabaca konuşursak, reCAPTCHA’nın altında yatan sistem, daha önceden 3+ kişinin cevabıyla okunmuş (doğru cevabı bilinen) bir sözcüğün yanına cevabı bilinmeyen bir sözcüğün getirilip yine 3-5 kişiye sorularak cevabın oylanmasıyla çalışıyor. [3] İlginç bir özellik:
reCAPTCHA’da sorulan iki kelimeden sadece birine doğru cevap verip ikincisine asdfasdflkjhjk yazarak geçebiliyorsunuz. Fakat cevabı bilinen sözcüğün hangisi olduğunu doğru tahmin etmeniz gerek. %50 şansınız var. Gelin bu durumu inceleyelim. Bu ipucundan yola çıkılarak hazırlanabilecek bir reCAPTCHA kırıcı iki kelimeden sadece birini çözse güvenlik doğrulamasından geçebiliyor. İşte kötü niyetliyseniz şansınız %100 arttı. :)
:idea: Başka bir açıdan yaklaşalım. Bir saldırgan grubu 10.000 farklı bilgisayardan durmadan reCAPTCHA form’larına, okuyucudan geçirip doğru tahmin ettikleri kelimenin yanında belirledikleri saçma bir kelimeyi (örn. asfdadsaf) yolluyorlar. Tahmin edersiniz ki bir süre sonra çoğunluğun oylamasıyla house gibi güzel kelimeler sistemde asfdadsaf olarak geçecek, böylece doğru cevap girenlerin cevabı kabul edilmeyecek, ve bir kere cevaplanan kelime kötü niyetli tayfa tarafından sisteme kaydedilip o kelimeye her defa denk gelindiğinde saçma cevap kullanılıyor olacak. Elbette bir süreden sonra bütün kelimeler teorik olarak bu saçma cevaba sahip olacaklar. :) Elbette önlenebilir, ama çok sayıda IP adresi ve cevap olarak sunulan saçma kelimelerle işler zorlaştırılabilir.
Kötü niyeti bir kenara bırakalım, reCAPTCHA whitepaper’larında okuyacağınız üzere aslında sistemin çoğunluğu (doğal olarak) yabancılar ve İngilizce kelimeleri hatalı yazabiliyorlar. [3] Bu nedenle bir kelimenin yanlış cevabı oylamayla doğru kabul edilebiliyor. Ama bu o kadar da sağlam bir argüman olmaz. :) En son argümanda bu konuya döneceğim.
# reCAPTCHA Üçüncü Parti Bileşendir ve Yavaşlatır
Kendi sunucunuz üzerinden CAPTCHA sunmak ile ReCaptcha arasında aslında çok fark var. :) Sitenize kurduğunuz recaptcha formu üzerinde çalışacak olan JavaScript’ten tutun, captcha’nın kendisi dahil bütün resimler. http://www.google.com/recaptcha/api/image?c=... şeklinde bir adresten geliyor ve kullanıcının tarayıcısından isteniyor.
Google IP’lerinin (Analytics, YouTube, Maps, Docs, Apps) Türkiye’de uzunca bir süre yasaklandığını hatırladınız mı? [5] Peki ya google.com/recaptcha da mahkeme kararıyla yasaklanırsa? Kullanıcılarınızın %95’i güvenlik doğrulamasından geçemeyecekler ve sitenizin kayıt formu %95 ihtimalle çalışmayacak. Bu yüzden Recaptcha kurduğunuz sitenizde bir satır kodu değiştirerek (switch görevi görecek şekilde) kendi CAPTCHA çözümünüze geçebilmeniz gerekir. Sonuçta reCAPTCHA sitenizde üçüncü parti bileşen olarak çalışır ve sisteminizi onun üzerine kurarsanız sisteminiz iptal olabilir. :) Emin olun Facebook, Twitter vb. hepsinin bu yedeği vardır. :) Bu konuda benim gözümü açan Umut‘a teşekkürler.
Aslında Google sunucularıyla etkileşen kısım sadece kullanıcının tarayıcısı değil. Kullanıcının verdiği doğrulamak acaba reCAPTCHA sunucularına gitmek zorundasınız. Recaptcha’yı sitenizde yapılan her işleme yerleştirdiğinizi ve kullanıcı sayınızın inanılmaz hızla arttığını düşünün. Google sunucuları bunu kaldırabilir, peki ya sizin çıkışlarınız bu kadar hızlı mı? Bu kadar bağlantıyı ölçekleyebilecek misiniz? Cevabı doğrulama işlemini en kısa sürede yapıp kullanıcıya yanıt sürenizi (response time) düşük tutabilecek misiniz? Bunu nasıl çözersiniz? :idea:
Öncelikle her dil için hazır sunulan reCAPTCHA kütüphanelerini kullanmamalısınız. Ölçeklendirme için karşı bağlantıları kendiniz açıp kapatabileceğiniz bir implementasyona ihtiyacınız olacak, bunu da büyük ihtimalle kendiniz yazacaksınız. Bir yerden sonra karşı sunucuya açılma işini birden fazla sunucu yapmak zorunda kalacak ve bu işi de implementasyona dahil etmek zorundasınız. Sunucularınız da Google’ınkilere ne kadar yakın olursa (en azından yakın omurgalarda) o kadar yüksek throughput alırsınız. :idea: Peki bu sorunu Google nasıl çözebilir? Eğer Google, kendi sunucunuzda çalıştırabileceğiniz bir reCAPTCHA motoru sunarsa, hazır 50.000 sözcük gibi güncellenebilir bir dağarcıkla cevabını bildiğiniz kelimeleri kullanıcılara sorarsınız. Bu defa da “re"CAPTCHA amacından sapar, ve zaten aynı işi yapan kütüphaneler (sözlüğüyle beraber ör. JCaptcha) var. Yani yerelinizde çalışan bir Captcha servisinizin olması en ideal ve hızlı çözüm. Böylece kullanıcılarınıza da iki yerine bir kelime sormuş olursunuz. Recaptcha da Google’ın kapalı kaynaklı ürünlerinden biri olarak kalır.
# Şeytansı reCAPTCHA
Don’t be evil! :twisted: Google’ın şu meşhur sloganı. :) Peki Google aslında sizin (recaptcha’yı sitesine koyan masum geliştirici) sitenizle ilgili hangi bilgilere ulaşabilir? Google Account’unuz ile domain‘inize (alan adınıza) özel aldığınız API anatharı ile reCATPCHA’yı sitenize kurdunuz. Kullanıcılar
google.com/recaptcha/...üzerinden resimleri sorgulamaya başladılar.
İşte bu dakikadan sonra Google’ın elinde sitenizin reCAPTCHA’lı kısmını günde kaç kişi ziyaret ediyor, ziyaret edenlerin kullandığı tarayıcı hangisi, IP adresleri neler, hangi ülkelerden bağlanıyorlar, verdikleri doğru cevap yüzdesine göre zeka seviyelerine kadar bir çok analitik bilgi var. :evil:
Ücretsiz Google Analytics, Gmail, Search History, YouTube gibi onlarca Google servisini kullanan biri olarak privacy’nin (kişisel gizlilik) sallantıda olduğu günlerde Google Master Plan‘a inanmıyor değilim. 8-O
En basitinden oylama sonucu bulunan doğru yanıtları sistemi iyileştirmede kullanan Google “dünyanın en güçlü OCR okuyucusu"nu yapacak ve belki de açık kaynak politikasının tersine gidip parayla satacak! :evil:
# Dünyanın Sonu ve Okunamayan Resimler
Felsefi argüman… Elbette bu captcha’ları çözüyoruz çözüyoruz, Google da bir yandan saatte 1000 sayfa kitap tarayabiliyor. [4] Peki ya bir gün gerçekten çözülemiş kelimelerin sonuna gelirsek? O halde reCAPTCHA dünya üzerindeki görevini tamamlıyor olacak ve biz de lokal kurulumdaki captcha çözümüze mi döneceğiz? Önümüzdeki yıllarda Recaptcha’ya neler olacak? Bunların hiçbirine verebilecek kesin cevaplarımız yok.
Belki de bundan beş yıl sonra captcha çözümleri tarihe karışacak, ama o tarihe kadar kolay kurulum ve kullanımıyla reCAPTCHA’nın modasını sürdüreceği aşikâr.
# Her Kullanıcı için Kullanışlı mı?
Aslında kullanışlılık meselesi üstteki argümanla desteklenebilecek bir argüman ve eminim bunu çoğunuz da gözlemlemiştir: Recaptcha’da artık matematik-fen kitapları taranıyor olsa gerek ki kesirli-integralli matematiksel ifadelerle karşılaştığımız oluyor ve kimse bunlara cevap veremediği için bunlar sürekli birilerinin karşısına çıkıyor. Tüm böyle cevaplanması zor ve okunaksız resimlerin sistemdeki sayısı git gide artıyor.
[caption id=“attachment_1614” align=“aligncenter” width=“344” caption=“Okunamayan Captcha’lar”] [/caption]
[/caption]
Peki ya “iki” kelime? Kullanıcılarınız o upuzun İngilizce kelimeleri cevaplamak zorunda mı? Ben bile çoğu zaman hızlı yazarken hata yapıp geçiyorum. Unutmayın, kullanıcınız kendini zorlayan yerlerde gerginleşir ve siteden erken ayrılma isteği duyar. Google bir süre daha çözülecek kelimelerin İngilizce olmasına bir çözüm bulamayacak gibi görünüyor.
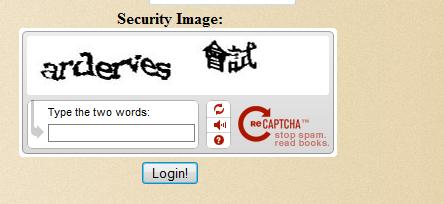 Peki ya taranan Çince kitaplar? Alın size bir kullanılabilirlik problemi. :) İnanın, nadir rastlanan bir durum değil. Git gide de sıklaşıyor.
Peki ya taranan Çince kitaplar? Alın size bir kullanılabilirlik problemi. :) İnanın, nadir rastlanan bir durum değil. Git gide de sıklaşıyor.
# Sonuç
Bir makalenin daha sonuna gelirken o kadar konuştuktan sonra bir sonuca varmamız gerek. Ama başta da dediğim gibi bu sadece bir kritikti. Elbette reCAPTCHA’yı kullanmakta büyük bir sakınca yok. Projenin arkasında Google ve onun değerli mühendisleri var, ve bir şekilde bu argümanların antitezlerini bulacaklardır, çözümler geliştireceklerdir.
Bu konuda sohbet etmek isteyen varsa bana ulaşsın, zevkle tartışırız. Eminim daha bir çok argüman vardır. 8-)
Not: “Sucks"ın Türkçe’sini bulamadım. Zaten başlık da sansasyoneldi. :D :D
Referanslar
[1] European Commission “Europeana – Europe’s Digital Library: Frequently Asked Questions”. Press release. http://europa.eu/rapid/pressReleasesAction.do?reference=MEMO/08/724&format=HTML&language=EN. Retrieved 2008-11-26.
[2] Google Acquires Recaptcha - Official Google Blog
[3] reCAPTCHA: Human-Based Character Recognition via Web Security Measures - Luis von Ahn et al. - SCIENCE vol. 321. 12 May 2008; accepted 5 August 2008 Published online 14 August 2008; 10.1126/science.1160379.
[4] Kelly, Kevin (May 14, 2006). “Scan This Book!”. New York Times Magazine. Retrieved 2008-03-07.
Comments