Last month Google introduced GKE Autopilot. It’s a Kubernetes cluster that feels serverless: where you don’t see or manage machines, it auto-scales for you, it comes with some limitations, and you pay for what you use: per-Pod per-second (CPU/memory), instead of paying for machines.
In this article, I’ll do a hands-on review of GKE Autopilot works by poking at its nodes, API and run a 0-to-500 Pod autoscaling to see how well it scales from a user’s perspective.
- Cluster creation
- Poking at nodes
- System Pods (kube-system)
limitsvsrequestoverriding behavior- Autoscaling under pressure: zero to 500 pods
- Conclusion
# New Autopilot Cluster
GKE cluster creation has always been super simple, a single command that took you to a managed Kubernetes cluster:
gcloud container clusters create [NAME] [--zone=...|--region=...]
Autopilot is a single-word change in the command no different.
gcloud container clusters create-auto [NAME] [--zone=...|--region=...]
Creating the cluster took 6 minutes, which is a little longer than a single-zone GKE Standard creation took (3.2 minutes). I think it’s okay, since you probably are not creating tens of clusters per day.
As part of Autopilot, Cloud Console website also got a nice re-design that helps you choose a cluster type:
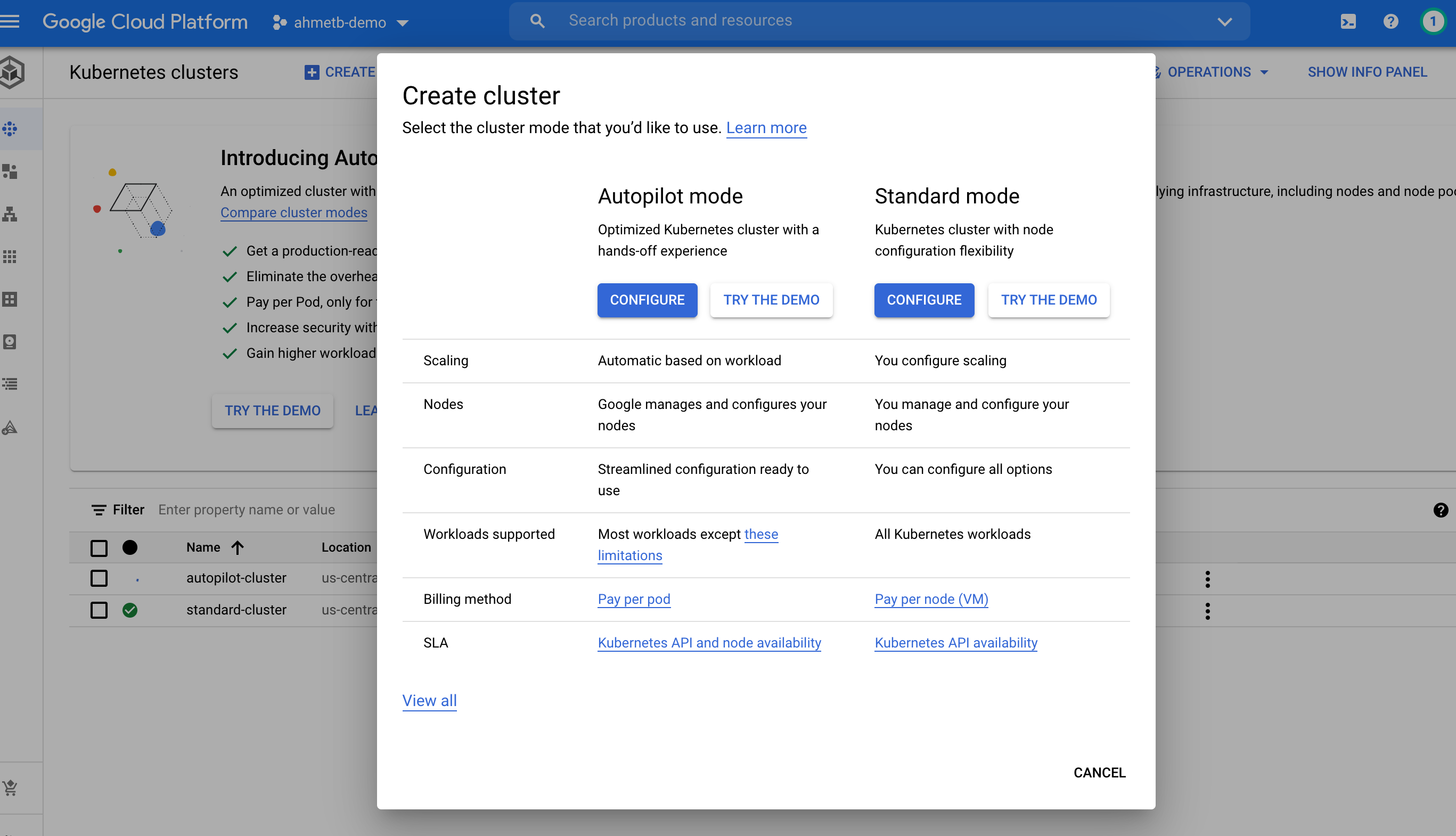
# Poking at Nodes
It seems my cluster has started with 2 nodes:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gk3-autopilot-cluster-default-pool-bcd71fbe-6qh9 Ready <none> 5m39s v1.18.15-gke.1501
gk3-autopilot-cluster-default-pool-cfb54b99-qsk7 Ready <none> 5m27s v1.18.15-gke.1501
Funny enough, GKE used to prefix VMs with gke-, but these are prefixed with
gk3-, and I’m not sure why (and it doesn’t really matter).
Unlike technologies like virtual-kubelet, there are still real nodes in the
cluster, but these VMs are inaccessible to me. If I list my Compute Engine VM
instances, I don’t see anything:
$ gcloud compute instances list
Listed 0 items.
However, if I run kubectl describe on these nodes, I can find their name,
compute zone and external IP address. This is enough information to attempt
to SSH into the node:
$ gcloud compute ssh --zone=us-central1-f gk3-autopilot-cluster-default-pool-cfb54b99-qsk7
This account is currently not available.
Connection to 34.123.136.111 closed.
As you can see, opening a SSH session to nodes is blocked by design. If you could get SSH access to an Autopilot node, you could run things on the node without going through the Kubernetes API. Google runs a vulnerability report program for (unintended) those who can get access to Autopilot nodes.
#
System Pods (kube-system)
You don’t have access to kube-system beyond querying objects. It’s a
readonly namespace to prevent tampering with the cluster components:
kubectl delete pods --all -n kube-system
Error from server (Forbidden): pods "event-exporter-gke-564fb97f9-5g5xj" is
forbidden: User "[email protected]" cannot delete resource "pods" in API group ""
in the namespace "kube-system": GKEAutopilot authz: the namespace
"kube-system" is managed and the request's verb "delete" is denied.
In the error message above, I notice there might be a custom authorization
layer ("GKEAutopilot authz") written in addition to Kubernetes’ RBAC. I’m
guessing this is done to prevent cluster admins from tampering with the
system namespace.
Here’s the list of Pods, nothing interesting stands out:
kubectl get pods -n kube-system
NAME READY
event-exporter-gke-564fb97f9-5g5xj 2/2
fluentbit-gke-224zv 2/2
fluentbit-gke-zvxkc 2/2
gke-metadata-server-4bdsq 1/1
gke-metadata-server-hvvm6 1/1
gke-metrics-agent-2kt54 1/1
gke-metrics-agent-rqp52 1/1
kube-dns-57fcf698d8-4jtzc 4/4
kube-dns-57fcf698d8-nmwrt 4/4
kube-dns-autoscaler-7f89fb6b79-vg7gx 1/1
kube-proxy-gk3-autopilot-cluster-[...] 1/1
kube-proxy-gk3-autopilot-cluster-[...] 1/1
l7-default-backend-7fd66b8b88-wwfrv 1/1
metrics-server-v0.3.6-7c5cb99b6f-j8mxx 2/2
netd-bbct4 1/1
netd-ckd5z 1/1
node-local-dns-h9w2s 1/1
node-local-dns-vtmlk 1/1
pdcsi-node-bnzqm 2/2
pdcsi-node-l2gr8 2/2
stackdriver-metadata-agent-cluster-level-[...] 2/2
Based on my observation, GKE runs at least 2 nodes at all times to host these
cluster components. You are not paying for these kube-system
pods, but there’s a per-cluster/hour fee ($0.10/hour) with the
first cluster free.
# Resource Limits/Requests and overriding behavior
GKE Autopilot is somewhat restrictive when it comes to CPU and memory requests: CPU requests are allowed in 250m increments (10m for DaemonSets), and there’s a 1.0-6.5 range allowed between CPU-to-memory GiB.
I wanted to see what happens if I specify an invalid cpu or memory
combinations on my Deployment, as well as different requests vs limits.
I found out that:
- Autopilot replaces
limitswith givenrequests - invalid CPU/memory values are rounded up to a valid value.
When GKE Autopilot silently overwrites limits with the requests (or
corrects the cpu/memory specs to allowed values), there’s no visible
warnings or errors. However, Autopilot adds a autopilot.gke.io/resource-adjustment
annotation on the Deployment when a resource config is overridden (and I’m
told it will soon present a kubectl warning when this happens).
Cloud Run is similar in this regard (you’re charged for memory/CPU
during requests to container instance) as it ignores requests and uses limits.
When you specify a value that’s invalid, the control plane will round-up your
input to the nearest value silently. 1 For example cpu: 100m becomes
250m, and 255m becomes 500m.
I tried to see which component overrides the resource spec inputs, but since
querying mutatingwebhookconfigurations is forbidden2, I could not find anything.
I also browsed apiserver /logs endpoint through kubectl proxy, but could
not see any messages or Kubernetes Event objects that warns the user about this
behavior.
# Autoscaling under pressure (0→500 Pods)
Before we start, it’s useful to remind yourself that Kubernetes is not really designed for rapid scale-up events, since there are still machines that need to be provisioned under the covers. That’s why typically Kubernetes users over-provision the compute capacity and leave some room for dynamic scaling based on load patterns.
Keep in mind that, the autoscaling scenario we’re about to try is possibly the worst case scenario and you would very rarely need to go from 0-to-500 pods in a very short timeframe.
That said, it’s possible to add spare capacity to GKE Autopilot by creating “balloon pods” that hold onto the nodes and get preempted when there are actual workloads to run on these nodes (such as burst scale-up).
If you want the ability to have burst scaling (e.g. 0-to-1000 instances instantly), without pre-provisioning infrastructure, you might want to check out Cloud Run.
Now let’s put the autoscaling promise to see how fast the cluster will scale up to meet the demand created by the unscheduled Pods. I will deploy a 500-replica Deployment using the minimum allowed resources (250m CPU, 512 MiB memory).
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 500
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: app
image: nginx
resources:
limits:
memory: "512Mi"
cpu: "250m"
NOTE
By deploying too many Pods, we easily run out of capacity, which triggers the cluster autoscaler to add many more nodes to the cluster, which in turn triggers a master resize event on GKE.
The master resize happens on GKE because GKE the VMs that run the the Kubernetes API server and etcd need to be resized to a higher machine type when the node count gets larger.
This would normally mean Kubernetes API downtime, but Autopilot clusters are regional, which means we run 3 master nodes in different zones, and therefore the Kubernetes API stays up. While this event is happening, your GKE cluster will show status RECONCILING.
Below are the observed results from the first test run.
Node count over time (first run):
| t | Ready | NotReady |
|---|---|---|
| 0 | 2 | 0 |
| 2m | 2 | 13 |
| 3m | 3 | 40 |
| 5m | 7 | 36 |
| 7m | 25 | 19 |
| 10m | 29 | 16 |
| 11m | 40 | 5 |
| 13m45s | 48 | 0 |
Pod count over time per phase (first run):
| t | Running | NotReady |
|---|---|---|
| 0 | 0 | 0 |
| 10s | 1 | 44 |
| 1m30s | 1 | 110 |
| 3m50s | 1 | 405 |
| 4m | 7 | 403 |
| 6m | 114 | 329 |
| 9m | 250 | 146 |
| 13m | 473 | 26 |
| 14m | 500 | 0 |
We reached 500 running Pods in 13 minutes; however, I could not help but notice:
-
It took 4 minutes for 400 out of 500 Pods to have record on the API (even as Pending). I think this is because of the ongoing “master resize” event (though there might be also some rate limiting), but it did not reproduce on the second run.
-
Time to run the second Pod is about 4 minutes. It reproducibly requires a new node to be provisioned to run the second Pod. (It seems there’s only enough leftover space in the first two nodes running system pods.) This takes several minutes, so it might feel awkward while getting started.
Upon further testing, it seems this has happened due to the “master resize” that occurred due to growing cluster size. Further testing showed that it takes roughly 1.5 minutes to add a new node to run a “pending” Pod.
-
Cluster autoscaler could not immediately determine how many nodes it needed to run. The cluster eventually reached 48 nodes, but the autoscaler took several minutes to realize we need ~40 nodes.
-
There are over 200 Pods left in
OutOfpodsandOutOfcpustatus, which means the node has hit its max Pod count or ran out of CPU allocation. This doesn’t impact functionality, but it definitely pollutes thekubectl get podsoutput, and there doesn’t seem to be a controller cleaning these API entries. They seem to stay there as long as the underlying ReplicaSet exists. -
When I ran the test run again, I noticed the same workload has fit in 35 nodes (as opposed to 48). I don’t know why this disparity occurs, but it does not impact the GKE Autopilot users since you wouldn’t be paying for the nodes.
-
Despite deploying 500 identical Pods, the underlying nodes were created using a cocktail of
e2-micro,e2-medium,e2-standard-4,e2-standard-8machine types. Similar to the previous bullet point, I think the autoscaler does not act deterministically and the timing of pending pods influence the decisions.
Below are the observed results from the second test run. I deleted the first Deployment (and let the worker nodes scale back to 3). Now that we have larger master VMs that will not be resized during the deployment:
Node count over time (second run):
| t | Ready | NotReady |
|---|---|---|
| 0 | 3 | 0 |
| 2m | 8 | 29 |
| 2m30s | 37 | 0 |
Pod count over time per phase (second run):
| t | Running | NotReady |
|---|---|---|
| 0 | 2 | 141 |
| 1m | 26 | 474 |
| 2m20s | 105 | 384 |
| 2m40s | 497 | 2 |
| 3m | 500 | 0 |
The second run shows that after the master resize occurred, scaling up the cluster by adding more nodes, and reaching 500 Pods is a lot quicker. This time we reached 500 running Pods in 3 minutes!
# Conclusion
I’m excited about GKE Autopilot. Finding the optimal size for your cluster and nodes can be quite tricky. GKE Autopilot solves that problem (and a lot more) for you, and gives you Kubernetes API as the abstraction layer.
As with all managed services, it may seem more expensive per compute unit (CPU/memory/seconds) compared to GKE Standard. However, comparing GKE Autopilot and GKE Standard is not apples to apples.
GKE Autopilot can be cheaper3, considering the engineer-hours, the opportunity cost and the total cost of ownership (TCO) that you would spend managing a cluster and and ensuring high utilization on the nodes you’re paying for.
Watch this space, as I think GKE Autopilot will become the preferred way of running Kubernetes workloads on Google Cloud and the list of limitations will only get shorter from here.
Hope you enjoyed this review. Follow @WilliamDenniss and his blog (as well as GKE product blog) to keep up with GKE Autopilot news. (Thanks to the GKE Autopilot team for reading drafts of this and providing corrections.)
-
An invalid CPU/memory combination could’ve been an error in the API, but that would make migrations from GKE Standard harder. Similarly, AWS Fargate also rounds up CPU/memory configurations. ↩︎
-
I’m not sure why listing
mutatingwebhookconfigurationsis forbidden. (I realize creating mutating webhooks is forbidden, which is a current limitation of Autopilot.) That being said, you can list/writevalidatingwebhookconfigurations. ↩︎ -
Not to mention, you are not paying for the OS/kernel overhead and the compute resources used by
kube-systempods which take away from your “node allocatable” space that you pay for in GKE Standard. ↩︎